How does this work with heap allocation? When you free memory and then allocate it again and get back the same address range, wouldn't the flag still apply to the new block?
madvise() works at the page level and if you're using madvise(), then you're expected to be using mmap() to allocate pages explicitly. It would be unusual and a bad idea to start madvise()ing memory that's being handled by an allocator (like malloc).
Of course you could also write a security focused heap allocator that uses these madvise() options under the hood.
Before I clicked I was expecting this to be a "random numbers as a service" announcement, based on lava lamps or something.
And yes I know CloudFlare did the lava lamps thing, like a bunch of other people did it before them. But it would be totally inline with Amazon to have a random numbers as a service service to compete with random.org.
I have always wondered why they aren't using plasma globes instead of lava lamps. Not only would it give a higher bandwidth, but it would also be a lot more energy efficient.
>" Firstly, as mentioned, s2n uses the so-called “Prediction resistant” mode, which means that s2n feeds the random number generator with more entropy (from hardware) on every call, as long as the right hardware is available"
Would this be the RDRAND instruction or something else?
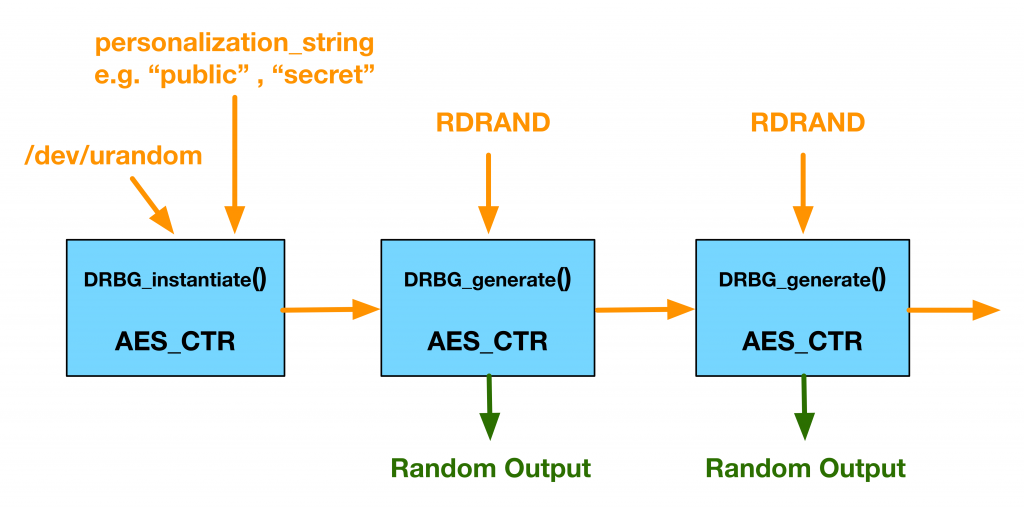
We use RDRAND if it's available, and we also have our own hardware entropy generators in some systems. In either case, we use this entropy as additional input that provides prediction resistance, and it's fed into the AES_CTR generator. Here's a picture from the blog post:
Basically when the DRBG is initialized we start with /dev/urandom and the personalization string. That sets up the initial state, and then hardware entropy is "mixed in" every time the generator is used. Because the mixing in happens before AES is applied, that means that even if either stream of entropy is biased, AES will randomize it anyway (or else AES is a broken cipher!). That means that even if you controlled both inputs, it would still require at least as much computational work as it takes to compute AES to be able to generate a predictable output. That's a nice property of the DRBG construction.
This bit is an aside but it's interesting to me: "Earlier this year, with Galois, we completed a proof of our implementation of AES_CTR_DRBG, and formally verified that our code in s2n is equivalent to the written specification." That's amazing! I think it may be the first bit of provably correct code that I'm likely to actually use in practice.
> Recently, both the OpenSSL and glibc projects have been looking to replace their random number generators. They, too, are going with AES_CTR_DRBG, based in some part on the work in s2n and the availability of formal verifications that can be applied to code. That’s pretty sweet.
I tried to search for this csprng in glibc, but I wasn't able to find anything. Can anyone provide more info?
So we mark our super secret entropy memory area WIPEONFORK. Now we fork and our super secret entropy memory area feeding all RNG is all zeroes. We've implemented a Sony RNG!
So we still need to detect forks. Not sure this is entirely the silver bullet this makes it out to be. Maybe fork() is just a bad idea, for any number of reasons.
Wiping the page sets all of the data back to 0, just as it was on initial process launch. The keys are wiped, but so is your BOOL IsInitialized, so you would seed from hardware entropy the same way the parent process did when it saw that the generator wasn't initialized.
bmm6o's reply captures the approach; you WIPEONFORK a guard variable, and use the state of that variable to re-initialize.
When we're writing a crypto library, like s2n, or OpenSSL, we don't get a choice to avoid fork() ... the application can fork() any time it wants and we just have to be able to deal with it. There have been a few approaches:
* Always feed new entropy on every call (but this isn't always available)
* Use getpid() to detect a fork() ... but this can break because some versions of libc cache the value of getpid(). Another problem is the grand-child problem, where an application can fork(), have have the child start a new process group, then the parent exits, then the child fork()s again ... in that situation there's some chance that the grandchild ends up with the same PID as the original process that started everything (and may have used the RNG).
* To fix that, one clever approach that BoringSSL used for a while was to check both getpid() and getppid(), which signaficantly reduced the likelihood of occurrence but was still probabilistic.
* All sorts of weird clone() flags, that things like language runtimes and virtual machines use, can bypass pthread_atfork and PID changes.
What's wrong with setting it DONTFORK and handling the page fault in the process? Someone can still prevent you from correctly handling the fault in the new process, but at least that keeps the RNG in an obvious broken state.
Right now, the <4.14 fallback seems strictly worse.
(Disregarding that this is mostly academic, and that whoever is calling fork() while using your library is unlikely to have spent the same attention to detail when it comes to stuff like ephemeral keys..)
I couldn't make this work reliably ... the kinds of applications that call clone() directly and bypass the pthreads stuff are language runtimes and VMs that want to emulate their own lightweight processes. They also have their own page fault handling, and documentation says that behavior is undefined when these things start interacting recursively. It's very difficult for a library to exert control.
At a same time these environments often use native crypto that's implemented in C, for performance, and so it all comes together. Of course the other mitigations present still work, and we're talking about a very very obscure and unlikely set of circumstances, but why leave even a tiny door open.
Wow, that's a cool trick - personally, I didn't know this is possible. Does it mean a system call and context switch for every check though?
One thing I like about the MINHERIT_ZERO/MADV_WIPEONFORK approach is that it's basically just a low-cost cache-friendly memory lookup at run-time, the only expense is at fork time.
Sounds like bad news for 99.9% of the world not running 4.14 and the messy backwards compatibility path they have to maintain forever. That part of the code is already screaming "goto fail":
We can't change history, only improve the future. There are three levels of defense, precisely because until now there's been no way to robustly detect a fork(), but it will be nice to nail that for 4.14 and beyond and fleets can move surprisingly quickly to newer kernel versions and get the benefit of that.
I think we have a high bar for a code readability and that the code isn't screaming goto fail. Though we do hate ifdef's and goto's and that file is one of the few places we have any, again precisely because of the ickyness of the challenge prior to 4.14. But if it helps reassure you, we also have a test case to make sure that the fork detection works:
Was trying to see how a 1960s machine is relevant to a discussion of brand new linux syscall behavior... Took me a while to see that the systems of today will look like the 60s do to us in ... The late 2060s. So if the 2067 tax database picks up an older kernel than this new madvise flag they are hosed, for some definition thereof (more like they need to be more careful when forking RNGs).
The option can be used to robustly reset a guard variable, and hence
re-initialize an RNG, DRBG, PRF, or other generator where duplicate state
across processes would be a security issue.
I'm still experimenting with the best approach. On Linux fork() clones a single thread's context, and since we know there's no call to fork() between the line of code checking the guard and the lines of code generating data, we don't need to worry about that so much (the RNGs are thread local).
But re-entrancy might be a problem ... e.g. if some crazy application writer has called fork() from a signal handler, and that happened right between those lines. For a case like this, I think moving the guard to post-generation (but pre-use) and using an atomic CAS option to have the guard effect the return value of the generator, can do the trick at the cost of having to very occasionally throw generated data away. But I haven't tried it on all platforms.
Crazy is the correct word here. glibc's fork() implementation is not async-signal-safe (even though POSIX currently says it should be), so you're going to have a bad time if you fork from a signal handler.
Sorry, I missed this comment when I brought the issue up below. (I was on my phone, which is sort of an excuse...)
With a thread-local RNG (and a thread-local page which gets zeroed on fork) it sounds like you're probably best off extracting data from the RNG and then checking the flag to see if you need to go back and try again. The only cost of doing it this way is a very marginal extra cost whenever you need to regenerate entropy -- but you can think of that as just being a slight increase in the cost of the fork.
The only other question which comes to mind is whether you need to worry about breakage on systems which have weaker-than-x86 cache coherency. I'm 99% certain that you're fine, but I'd prefer to be 100% certain.
I assume you'd like to see this functionality added to other platforms as well?
I had this exact same question. I guess you can make sure the code that checks and reads from the rng state can't fork in the middle of it (or call out to user code). But that only helps in the single-threaded case, what happens if you have another thread that is accessing it at the same time as the fork? Even if you check before and after, the initialized bool could be set again by the time you check after even though you just read a bunch of zeros.
A rng-per-thread combined with initialization check before and after might cover all the cases I think...
Why does that matter? The parent will eventually return from the signal handler and resume execution. What does fork have to do with anything? arc4random (or whatever you want to call it) isn't marked signal safe.
The child will also eventually return from the signal handler and resume execution. In the middle of the PRNG, thus returning the same random numbers in both processes.
I'm not sure what you mean by "arc4random isn't marked signal safe" -- you mean it can't be used in any process which receives signals?
{kind=link}
http://www.metzdowd.com/pipermail/cryptography/2017-November...